Introduction
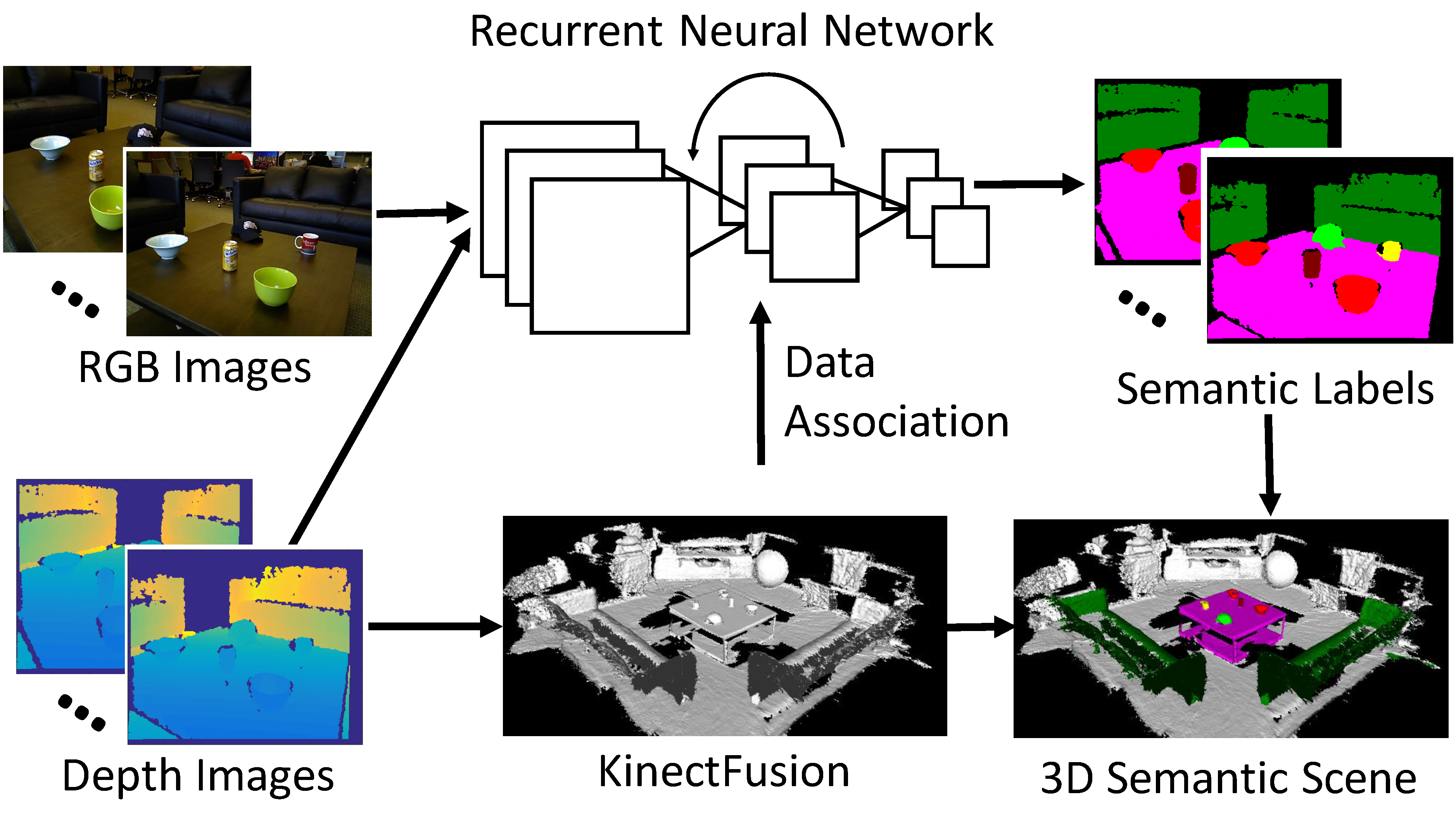
3D scene understanding is important for robots to interact with the 3D world in a meaningful way. Most previous works on 3D scene understanding focus on recognizing geometrical or semantic properties of the scene independently. In this work, we introduce Data Associated Recurrent Neural Networks (DA-RNNs), a novel framework for joint 3D scene mapping and semantic labeling. DA-RNNs use a new recurrent neural network architecture for semantic labeling on RGB-D videos. The output of the network is integrated with mapping techniques such as KinectFusion in order to inject semantic information into the reconstructed 3D scene. Experiments conducted on a real world dataset and a synthetic dataset with RGB-D videos demonstrate the ability of our method in semantic 3D scene mapping.
Publication
Yu Xiang and Dieter Fox. DA-RNN: Semantic Mapping with Data Associated Recurrent Neural Networks. In Robotics: Science and Systems (RSS), 2017. arXiv
Code and Datasets
The code of DA-RNN and the datasets we experiment are available here.
Acknowledgments
This work was funded in part by ONR grant N00014-13-1-0720 and by Northrop Grumman. We thank Tanner Schmidt for fruitful discussions and for providing his implementation of KinectFusion.
Result Video
Contact : yuxiang at cs dot washington dot edu
Last update : 6/30/2017